
走进安全行业大模型
发布时间 2024-04-11在大模型出现之前,以机器学习、深度学习、规则推理等为代表的人工智能技术已经广泛应用于网络安全领域了。那么为什么还需要大模型呢?
为什么需要大模型?
因为大模型不仅具备通用智能和知识,还具备知识整合提取能力和逻辑思维能力。理想的大模型像是人类的助手(或者说副驾驶),而不是一个可供查阅的工具书。
以通过深度学习训练得到的专用小模型为例。小模型的训练需要大量的标注数据,而且只能解决单一问题。相比之下,大模型的通用性灵活很多,甚至只需要几条简单的样例,就能具备新能力,这就使得大模型有更广泛的应用场景。
OpenAI在2020年提出的缩放定律(Scaling Law)指出,模型的最终性能主要与计算量,模型参数量和数据大小三者相关,而与模型的具体结构(层数/深度/宽度)基本无关。
而大模型相比于之前的小参数量语言模型,在以上三个方面都做了巨大提升,并显现出一些涌现能力(世界知识,指令遵循,逐步推理等)。
通俗来讲,基础大模型由广泛的通用数据(如网页、百科、书籍等)训练得到,它像是一个可以和你对话的百科全书,了解却不精通各种知识,同时具备一定的逻辑思维能力,而这些都是过往小模型很难做到的。
截至2023年底,国内已发布的通用大模型超过了200个,那么为什么还要打造面向特定领域或行业的行业大模型呢?
为什么需要行业大模型?
上文提到了理想的大模型所具备的能力。然而,性能受限于缩放定律,基础大模型实际应用起来却并没有想象中那么得心应手。大模型使用通用语料库进行训练,而安全行业的数据通常是特殊且有限的。
这导致 LLM 缺乏安全相关数据和专业知识,对特定安全问题的理解能力匮乏,无法提供准确或深入的专业解释。
研究表明,通用大模型在安全问题上生成答案的准确率大都不足50%,对中文问题回答的准确率更低。下图展示的是不同模型在网络安全问题集上回答的准确率:
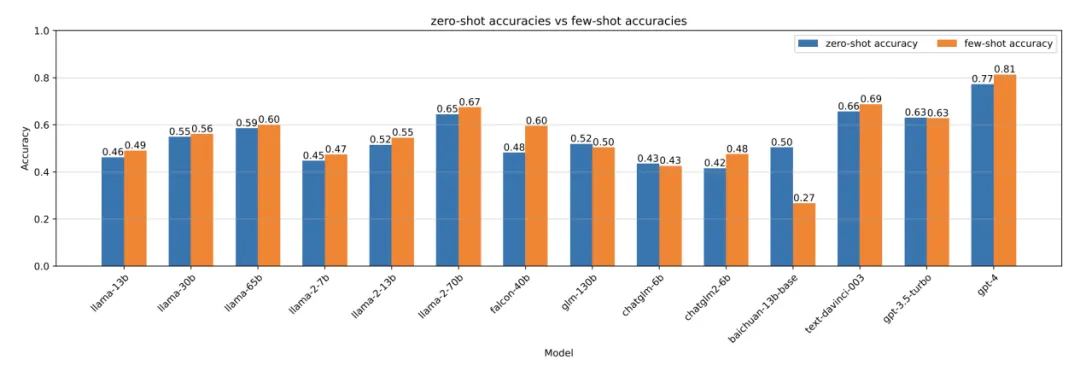
因此,通过增量预训练(Continuous Pre-train,CPT)等技术为大模型注入安全行业知识,就成为了安全行业大模型应用的必要手段。缺少这个步骤直接对后续安全任务做监督微调(Supervised Fine-tuning,SFT),大模型则或多或少会面临知识匮乏的问题,随即出现“幻觉”现象,对不懂的问题做出一本正经的回答。
从前面的描述可以看出,同样都叫“大模型”,但具体含义和适用范围上是存在差异的。那么大模型还有哪些层次划分呢?
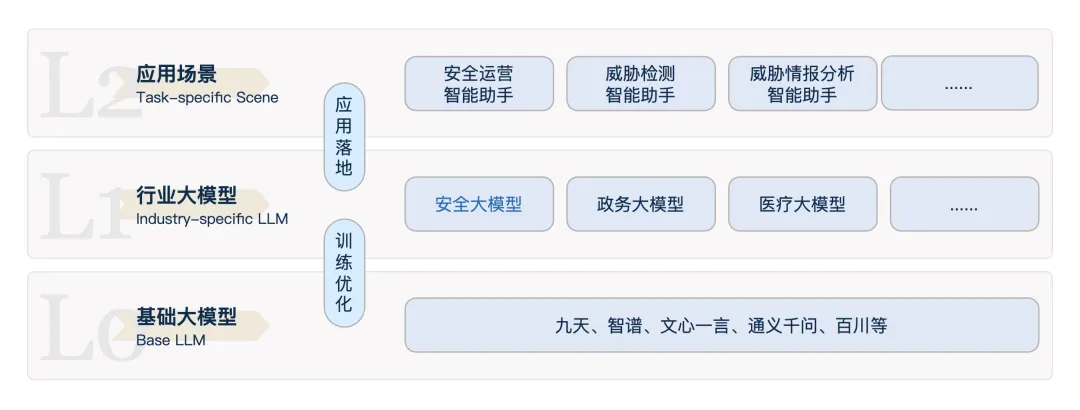
L0-L2大模型分层架构
为了加速大模型落地进程,可将大模型划分为L0基础大模型、L1行业大模型、L2应用大模型三个层次:
通俗来讲,L0基础大模型像是学习所有科目的高中生,L1行业大模型类似于选定专业的大学生,L2应用大模型则是选定特定方向的研究员。这种架构的优势在于,将大模型应用于业务的步骤流程化,加速整体落地进程,降低落地成本。同时,对于L0-L2层次的划分,也让业务数据的沉淀更加有条理,方便数据不断回流到大模型,不断优化大模型智能水平。
在我们关注的网络安全领域,有了安全大模型后,具体可以应用在哪些场景中,为我们的日常工作带来能力和效率的提升呢?
安全大模型的应用场景
安全大模型在L2层面具有广泛的应用场景。安全大模型通常允许用户通过自然语言输入的方式完成安全运营的日常操作,根据用户输入,按需调用已有的小模型和产品功能,实现大小模型协同的智能算法体系。
这种自然语言调用功能模块的方式,可以利用大模型的知识储备和理解推理能力,为领域问题提供专业的解决方案。同时,对于已经有相关经验的安全专家,则可以通过大模型提升常规分析工作的效率。即“帮助普通人成为专家,帮助专家提升效率”。
下面列举一些常见的安全大模型应用场景:
应用场景1:安全运营
安全报告:大模型往往可以在几分钟内汇总指定范围内的所有告警事件,并且生成综合性安全报告,供安全专家查看。
告警解读:实现对于安全事件的关键要素,包括告警内容、事件类型、攻击手法、资产属性等进行专业分析和解读,生成解读报告,辅助用户告警研判。
告警溯源:对于特殊的告警,安全专家可以通过大模型进行进一步溯源分析,要求大模型根据终端日志生成溯源图等。
响应处置:基于事件信息和安全设备部署信息,由大模型自动生成事件处置策略,上报用户进去修改或确认, 实现对攻击行为的快速响应。
应用场景2:知识整合
安全问答:通过构建安全知识库,大模型可以回答用户的安全问题。用户可以查询各种网络安全、主机安全等方面的问题,并从回答中获取专业的安全信息和建议。
应用场景3:代码管理
漏洞修复:大模型可以根据漏洞分析结果,生成补救步骤、自动执行复杂的风险缓解活动或在无需用户交互的情况下修补软件,这大大加快了管理漏洞和提高组织安全性的速度。
恶意脚本:大模型可以分析和解释恶意脚本行为,协助用户发现存在威胁的脚本。它允许用户导入脚本并分析其是否存在恶意行为,检测和缓解潜在威胁,标记漏报和清除误报。
应用场景4:合规监控
数据大屏:大模型可以自动生成这些数据大屏来监控组织数据的合规性,可以帮助安全专家轻松跟踪合规目标的进度并向审核员展示。
合规修复:大模型可以通过合规性审计结果,提供相应的修复建议,帮助企业达到监管标准。
持续更新:随着行业标准的更新和管理机构更改其法规要求,合规审计往往需要做出相应变化。大模型可以快速的跟进这些变化,并提供指导建议。


 京公网安备11010802024551号
京公网安备11010802024551号